
|

|

|
|
|
|
|
文書オブジェクトモデル(DOM)とは、HTML文書およびXML文書のためのアプリケーション=プログラミング=インターフェイス(API)である。これは、文書の論理的構造や、文書へのアクセスや操作の方法を定義するものである。DOM仕様書においては「文書」という用語は広い意味で使われる。ますますXMLは数多くの異なる種類の情報を表現する方法として用いられつつあり、これらの情報は多様なシステムに貯えられる場合がある。この多くは伝統的には文書としてよりもデータとして見られたであろうものである。にもかかわらず、XMLはこのデータを文書として表わし、DOMはこのデータを処理するために使われる場合があるのである。
DOMを用いて、プログラマは文書を構築し、その構造をナビゲートし、要素や内容を追加、修正、削除することができる。HTML文書やXML文書の中で見つかるものは何でもDOMを使ってアクセスし、変更、削除、追加することができるが、例外も二三ある。特に、XML内部サブセットおよび外部サブセット用のDOMインターフェイスは、まだ仕様化されていない。
W3C仕様たるDOMにとって最も重要な目標は、広く多様な環境やアプリケーションで使うことができる標準的なプログラミング=インターフェイスを提供することである。DOMは、任意のプログラミング言語で使われるように設計されている。DOMインターフェイスについて正確で言語中立的な仕様を提供するため、我々はCORBA 2.2 仕様書に定義されているOMG IDLで仕様を定義することを選んでいる。OMG IDL版の仕様に加えて、我々は、Java および ECMAScript(JavaScript や JScript に基礎を置く工業規格スクリプト言語)用の言語バインディングを提供する。注意: OMG IDLは、インターフェイスを仕様化するための言語中立的かつ実装中立的な方法としてのみ使われる。他の多様なIDLも使うこともできないわけではなかった。一般的にIDLは特定のコンピューティング環境のために設計される。DOMは、どのようなコンピューティング環境でも実装でき、一般的にそうしたIDLに結びつけられるオブジェクト=バインディング=ランタイムを要求しない。
DOMは、文書のためのプログラミングAPIである。これは、それがモデル化する文書の構造によく似ている。たとえば、あるHTML文書から取られたこのテーブルを考えてみよう。
<TABLE>
<TBODY>
<TR>
<TD>Shady Grove</TD>
<TD>Aeolian</TD>
</TR>
<TR>
<TD>Over the River, Charlie</TD>
<TD>Dorian</TD>
</TR>
</TBODY>
</TABLE>
DOMはこのテーブルをこのように表現する。
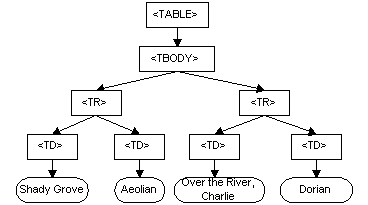
DOMにおいて、文書はまさに樹のような論理的構造をもつ。厳密には、2本以上の樹を内容とすることもできる「林」や「森」のようなものである。しかしながら、DOMは、文書が樹や森として実装されなければならないと規定するわけでもなく、オブジェクト間の関係の実装方法を規定するわけでもない。DOMは、任意の便宜な方法で実装してよい論理的モデルである。この仕様書では、我々は文書の樹に似た表現を記述するために構造モデルという用語を使う。我々は、特定の実装を暗示することを避けるために、明示的に「樹」や「森」というような用語を避けるのである。DOM構造モデルの重要な特性の1つは構造同型性 (structual isomorphism) である。どの2つのDOM実装が同じ文書の表現を作成するために使われても、それらは全く同じオブジェクトや関連性がある同じ構造モデルを作り出すのである。
「文書オブジェクトモデル」という名前は、それが伝統的なオブジェクト指向デザインの意味での「オブジェクトモデル」であることから選ばれた。文書はオブジェクトを使ってモデル化され、モデルは文書の構造だけでなく、文書のふるまいや文書を構成するオブジェクトを包含する。換言すると、上記の例におけるノードはデータ構造を表現せず、関数および同一性を有するオブジェクトを表現するのである。オブジェクトモデルとして、DOMは次のものを識別する。
SGML文書の構造は、伝統的にはオブジェクトモデルではなく抽象的データモデルによって表現されてきた。抽象的データモデルでは、モデルはデータの周囲に寄せ集められる。オブジェクト指向プログラミング言語では、データ自体はデータを隠蔽するオブジェクトの中にカプセル化され、直接の外部的操作から保護される。オブジェクトをどのように操作してよいかを決定するのは、これらのオブジェクトに結びつけられた関数であり、これはオブジェクトモデルの一部分である。
DOMは現在のところ2つの部分からなっている。DOMコアと DOM HTML とである。DOMコアは、XML文書用に使われる機能を表現し、また DOM HTML の基礎としても働く。DOMの準拠実装は、コアの章にある基本インターフェイスのすべてを、定義されている意味論をもたせて実装しなければならない。さらに、DOM HTML と拡張(XML)インターフェイスとのうち少なくとも1つを、定義されている意味論をもたせて実装しなければならない。
この節は、DOMのように見えるかもしれない他のシステムからDOMを区別することにより、DOMのより正確な理解を与えるように仕組まれている。
DOMは当初、JavaScript スクリプトや Java プログラムがウェブブラウザ間で可搬的にできるようにするための仕様として作り出された。「ダイナミックHTML」はDOMの直近の祖先であり、それは元来は広くブラウザに関して考えられていた。しかしながら、DOMワーキンググループがW3Cに結成されたとき、HTMLエディタやXMLエディタや文書レポジトリを含む他の領域のベンダーも加わった。これらのベンダーのうちのいくつかは、XMLが開発される前はSGMLに関して作業をしていた。結果として、DOMはSGMLのグローブや HyTime 規格に影響されている。これらのベンダーの中には、SGMLエディタやXMLエディタや文書レポジトリ用にAPIを提供するために、文書について独自のオブジェクトモデルを開発していたものもあり、これらのオブジェクトモデルもDOMに影響を及ぼした。
基本DOMインターフェイスでは、エンティティを表現するオブジェクトがない。数的キャラクタ参照や、HTMLおよびXMLにおける定義済みエンティティへの参照は、そのエンティティの置換をマークアップする単一のキャラクタで置き換えられる。たとえば、
<p>This is a dog & a cat</p>
では、"&" は "&" というキャラクタで置き換えられることになり、P 要素内のテキストは、一連の連続したキャラクタ列を形成することになる。数的キャラクタ参照や定義済みエンティティは、CDATA 部や、HTMLの SCRIPT 要素や STYLE 要素の中ではそうしたものとして認識されないから、それらの参照先のように見える単一のキャラクタで置き換えられない。上記の例が CDATA 部に囲い込まれていたならば、"&" は "&" で置き換えられず、<p> も開始タグとして認識されないことになる。一般的エンティティの表現は、内部的なものも外部的なものも、第1水準仕様書の拡張(XML)インターフェイスの内部で定義されている。
注意:文書のDOM表現がXMLまたはHTMLテキストとしてシリアル化されるとき、アプリケーションはテキストデータ内の各キャラクタをチェックして、数的参照や施定義済みエンティティを使ってエスケープする必要があるかどうかを確かめる必要があることになる。そうしないと、妥当でないHTMLやXMLとなりかねない。また、実装は、ISO 10646 を完全にはカバーしていないキャラクタエンコーディング ("charset") へのシリアル化は、そのエンコーディングで表わされないキャラクタがマークアップや CDATA 部にあれば失敗する場合があるという事実を認識するべきである。
DOMは、XML文書やHTML文書を処理するために使ってよいインターフェイスを指定する。これらのインターフェイスが抽象概念である -- C++ の「抽象的ベースクラス」によく似て、ある文書のアプリケーションの内部的表現にアクセスし、操作するための方法を指定する手段である -- ことを認識することは重要である。インターフェイスは、特定の具体的な実装を含意しない。DOMアプリケーションはそれぞれ、この仕様書に示されたインターフェイスがサポートされている限り、任意の便利な表現で文書を維持しても自由である。いくつかのDOM実装は、DOMインターフェイスを使ってDOM仕様書が存在するはるか前に書かれたソフトウェアにアクセスする既存のプログラムであるだろう。それゆえ、DOMは、実装依存性を避けるように設計されている。特に、
DOM1仕様書は、意図的に、文書構造および内容を表現および操作するために必要とされるメソッドに限定されている。将来の水準のDOM仕様書では、つぎの機能を提供する計画である。
|
|
|
|